

Архитектура ЭВМ
Автор: Куленчик Олеся Николаевна
Организация: ГБОУ школа №1236
Населенный пункт: г. Москва
Рассмотрены основные принципы построения цифровых вычислительных систем, работа логических блоков, организация и принцип работы памяти, взаимосвязь с периферийными устройствами, основы программирования процессора, создание файлов для конфигурирования системы, классификация вычислительных платформ.
Введение
Для XXI века характерна небывалая скорость развития науки, техники и новых технологий. Так от изобретения книгопечатания (середина XV века) до изобретения радиоприемника (1895г.) прошло около 440 лет, а между изобретением радио и телевидения – около 30 лет. Разрыв во времени между изобретением транзистора и интегральной схемы составил всего 5 лет.
В области накопления научной информации объем ее, начиная с XVII в. удваивался примерно каждые 10 – 15 лет. Поэтому одной из важнейших проблем человечества является лавинообразный поток информации в любой отрасли его жизнедеятельности. Подсчитано, например, что в настоящее время специалист должен тратить около 80% своего рабочего времени, чтобы уследить за всеми новыми печатными работами в его области деятельности.
Рынок современных компьютеров отличается разнообразием и динамизмом, каких еще не знала ни одна область человеческой деятельности. Каждый год стоимость вычислений сокращается примерно на 25-30%, стоимость хранения единицы информации – до 40%. Практически каждое десятилетие меняется поколение машин, каждые два года – основные типы микропроцессоров – СБИС, определяющих характеристики новых ЭВМ. Такие темпы сохраняются уже многие годы.
Сложность современных человеко-машинных систем, их функциональные особенности и степень автоматизации режимов управления определяются лавинообразным ростом быстроизменяющихся информационных потоков, параметрическое осмысление которых, и оперативное принятие управляющих решений осуществляет человек. Получение и анализ информации в этом случае должны происходить со скоростью выработки параметрических данных в реальном масштабе времени. При этом, в принципе, не существует объектов, исключающих непосредственное или опосредованное участие человека в функциональных контурах управления автоматизированных систем.
Прогресс в развитии микропроцессорной техники сделал ее доступной массовому потребителю, а высокая надежность, относительно низкая стоимость, простота общения с пользователем – непрофессионалом в области вычислительной техники послужили основой для организации систем распределенной обработки данных, включающих от десятка до нескольких сотен ПЭВМ, объединенных в вычислительные сети.
На сегодняшний день в мире существует более 130 миллионов компьютеров и более 80% из них объединены в различные информационно- вычислительные сети от малых локальных сетей (в офисах) до глобальных сетей (типа Internet). Всемирная тенденция к объединению компьютеров в сети обусловлена рядом важных причин, таких как ускорение передачи информационных сообщений, возможность быстрого обмена информацией между пользователями, получение и передача сообщений (факсов, E-mail писем), возможность мгновенного получения информации из любой точки земного шара, а так же обмен информацией между компьютерами разных фирм, работающих под разным программным обеспечением.
Вычислительные сети позволяют автоматизировать управление производством, транспортом, материально-техническим снабжением в масштабе отдельных регионов и страны в целом. Возможность концентрации в вычислительных сетях больших объёмов данных, общедоступность этих данных, а также программных и аппаратных средств обработки и высокая надёжность их функционирования – всё это позволяет улучшить информационное обслуживание пользователей и резко повысить эффективность применения вычислительной техники.
Измерение количества информации
Важным условием практического использования информации является ее своевременность и адекватность. Адекватность задает определенный уровень соответствия образа построенного на основе полученной информации реальному объекту. Адекватность выражают в трех основных формах:
- Синтаксическая адекватность – определяет сам процесс передачи ее скорость, точность, систему кодирования, наличие помех и т. п.
- Семантическая адекватность – учитывает смысловое содержание передаваемой информации, соответствие образа объекта и его реального аналога.
- Прагматическая адекватность – определяет соответствие полученной информации той цели управления, которая на ее базе реализуется.
Пример. Вы являетесь менеджером фирмы работающей на автомобильном рынке и получаете приглашение посетить выставку автомобильной техники. Данное приглашение содержит определенную информацию о месте, времени проведения выставке составе участников и т. д.
Если приглашение получено после закрытия выставки, то информация в нем будет уже не своевременной, а значит бесполезной потому, что ей нельзя воспользоваться. Для удовлетворения требованиям синтаксической адекватности бланк приглашения должен быть целым, изготовлен из плотной бумаги, шрифт легко читаемым, т.е. важен процесс передачи сообщения безотносительно содержания.
Семантическая адекватность требует, чтобы содержание сообщения в приглашении соответствовало действительности. Совпадали номера павильонов, имена участников, расписание мероприятий и т. п.
Прагматическая адекватность определяется полезностью сведений в приглашении. Если, руководствуясь приглашением, вы быстро найдете нужный выставочный павильон, вовремя попадете на семинар и тем самым сэкономите свое время и нервы, значит это полезная информация и требование прагматической адекватности выполнено.
Информацию можно измерить количественно, т.е. подсчитать. При подобных вычислениях абстрагируются от смысла сообщения, как отрешаются от конкретности в привычных для всех нас арифметических действиях (как от сложения двух яблок и трех яблок переходят к сложению чисел вообще: 2 + 3).
Оценка количества информации основывается на законах теории вероятностей, точнее, определяется через вероятности событий. Сообщение имеет ценность, несет информацию только тогда, когда мы узнаем из него об исходе события, имеющего случайный характер, когда оно в какой-то мере неожиданно. Чем больше интересующее нас событие имеет случайных исходов, тем ценнее сообщение об его результате и тем больше информации.
Рассмотрим простейший случай получения информации. Вы задаете только один вопрос: «Идет ли дождь?». При этом условимся, что с одинаковой вероятностью ожидаете ответ: «Да» или «Нет». Легко увидеть, что любой из этих ответов несет самую малую порцию информации. Эта порция определяет единицу измерения информации, называемую битом.
Выбор единицы информации не случаен. Он связан с наиболее распространенным двоичным способом ее кодирования при передаче и обработке. Если событие имеет два равновероятных исхода, это означает, что вероятность каждого исхода равна 1/2. Такова вероятность выпадения «орла» или «решки» при бросании монеты. Информация о таком событии равна 1 биту. Бит – минимальная порция информации, он может принимать два значения: 0 или 1. Если событие имеет три равновероятных исхода, то вероятность каждого равна 1/3. Сумма вероятностей всех исходов всегда равна единице: ведь какой-нибудь из всех возможных исходов обязательно наступит.
Событие может иметь и неравновероятные исходы. Так, при футбольном матче между сильной и слабой командами, вероятность победы сильной команды велика – например, 4/5. Вероятность ничьей намного меньше, например 3/20. Вероятность же поражения совсем мала.
Количество информации – это мера уменьшения неопределенности некоторой ситуации.
Кодирование информации
Информация – произвольная последовательность символов, т.е. любое слово, каждый новый символ увеличивает количество информации. Для измерения количества информации нужен эталон. Эталоном считается слово, состоящее из одного символа двухсимвольного алфавита (цифры 0 или 1). Количество информации, содержащееся в этом слове, принимают за единицу, названную битом. Имея эталон количества информации, можно сравнить любое слово с эталоном. Проще сравнивать те слова, которые записаны в том же двухсимвольном алфавите.
Для определения количества информации нужно найти способ представить любую ее форму (символьную, текстовую, графическую) в едином виде. Иначе говоря, надо суметь эти формы информации преобразовать так, чтобы она получила стандартный единый вид. Таким видом стала так называемая двоичная форма представления информации. Она заключается в записи любой информации в виде последовательности только двух символов.
Благодаря введению понятия единицы информации появилась возможность определения размера любой информации числом битов. Образно говоря, если, например, объем грунта определяют в кубометрах, то объем информации – в битах. Условимся каждый положительный ответ на заданный вопрос представлять цифрой 1, а отрицательный – цифрой 0. Тогда запись ответов образует многозначную последовательность цифр, состоящую из нулей и единиц, например 0100.
Например, если лекция состоится, вешаем табличку с цифрой 1, если нет – с цифрой 0. В 1 бите можно закодировать одно событие (свершилось или нет) – совершение одного из двух событий: есть лекция или нет лекции.
Для кодировки двух событий потребуется одна ячейка, для кодировки 4 событий нужны 2 ячейки:
00 – лекции нет; 01 – лекция есть;
10 – лабораторная работа; 11 – контрольная работа.
Когда известно, сколько будет событий, можно выбрать необходимое количество ячеек для их хранения. Для восьми событий надо 3 ячейки, т.к. 23 = 8. Для 16 событий надо 4 ячейки, т.к. 24 = 16. В 1 байте, т.е. в восьми ячейках может храниться 256 событий, т.к. 1 байт = 8 бит.
Процесс получения двоичной информации об объектах исследования называют кодированием информации. Кодирование информации перечислением всех возможных событий очень трудоемко. Поэтому на практике кодирование осуществляется более простым способом. Он основан на том, что один разряд последовательности двоичных цифр имеет уже вдвое больше различных значений – 00, 01, 10, 11, чем одноразрядная последовательность (0 и 1). Трехразрядная последовательность имеет также вдвое больше значений – 000, 001, 010, 011, 100, 101, 110, 111, чем двухразрядная, и т.д. Добавление одного разряда увеличивает число значений вдвое, это позволяет составить табл.1.5 информационной емкости чисел.
Таблица 1.5. Информационная емкость чисел
|
Число разрядов |
|||||||||||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
|
Количество различных значений |
|||||||||||||||
|
2 |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
2048 |
4096 |
8192 |
16384 |
32768 |
65536 |
Например, для того чтобы закодировать 32 буквы русского алфавита, достаточно взять пять разрядов, потому что пятиразрядная последовательность имеет 32 различных значения. Например, русские буквы представляются восьмиразрядными последовательностями следующим образом:
А – 11000001, И – 11001011, Я – 11011101.
Перед тем как кодировать любую информацию нужно договориться о том, какие используются коды, в каком порядке они записываются, хранятся и передаются. Это называется языком представления информации.
ПЭВМ является прибором, который управляется с помощью электрических сигналов. Поэтому любые данные должны быть некоторым универсальным образом представлены в виде электрического сигнала. Таким свойством обладают двоичная форма целых чисел. Для записи числа в двоичной форме используются только два символа 0 и 1. Эти символы легко поставить в соответствие некоторому фиксированному значению напряжения в электрических схемах ПЭВМ (рис. 1.20).
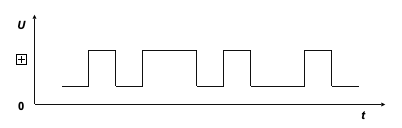
Рис.1.20. Поток данных в двоичной форме
Таким образом, все данные, с которыми работают ПЭВМ, представлены в виде двоичных чисел, а все действия с данными сводятся к комбинации трёх логических операций (табл.1.6.).
Таблица 1.6. Операции с двоичными числами
|
x |
y |
ИЛИ |
И |
НЕ х |
|
0 |
0 |
0 |
0 |
1 |
|
0 |
1 |
1 |
0 |
1 |
|
1 |
0 |
1 |
0 |
0 |
|
1 |
1 |
1 |
1 |
0 |
Количество информации, соответствующее двоичному числу, называют битом. Число, которое представлено N битами называется N-битным или N-разрядным. Количество информации, соответствующее 8 битам, называется байтом. Кроме того, используются группы, называемые словом. Размер слова зависит от характеристик конкретной ПЭВМ, но, как правило, он равен 2 или 4 байтам.
Представление числовой информации
В ЭВМ используются три вида чисел: с фиксированной точкой (запятой), с плавающей точкой (запятой) и двоично-десятичное представление.
У чисел с фиксированной точкой в двоичном формате предполагается строго определенное место точки (запятой). Обычно это место определяется или перед первой значащей цифрой числа, или после последней значащей цифрой числа. Если точка фиксируется перед первой значащей цифрой, то это означает, что число по модулю меньше единицы. Диапазон изменения значений чисел определяется неравенством:.
Полный текст статьи см. в приложении.
Опубликовано: 24.06.2021
Сертификат о публикации

Диплом участника конкурса

Лицензия Федеральной службы по надзору в сфере образования и науки (Рособрнадзор)

Регистрация в Федеральной службе по надзору в сфере связи, информационных технологий и массовых коммуникаций (Роскомнадзор)

Регистрация Российской книжной палаты, международный стандартный серийный номер ISSN: 2713-282X
